
最近在UE5内给项目做草地颜色与地表融合,其中用到了虚拟纹理。虚拟纹理在项目中已经非常常见了,正好借这个机会,整理一下虚拟纹理相关笔记。本篇作为整理性质的笔记,摘抄和参考了较多的文档和大佬文章,如需查看原文可以参考文章引用目录。
虚拟纹理
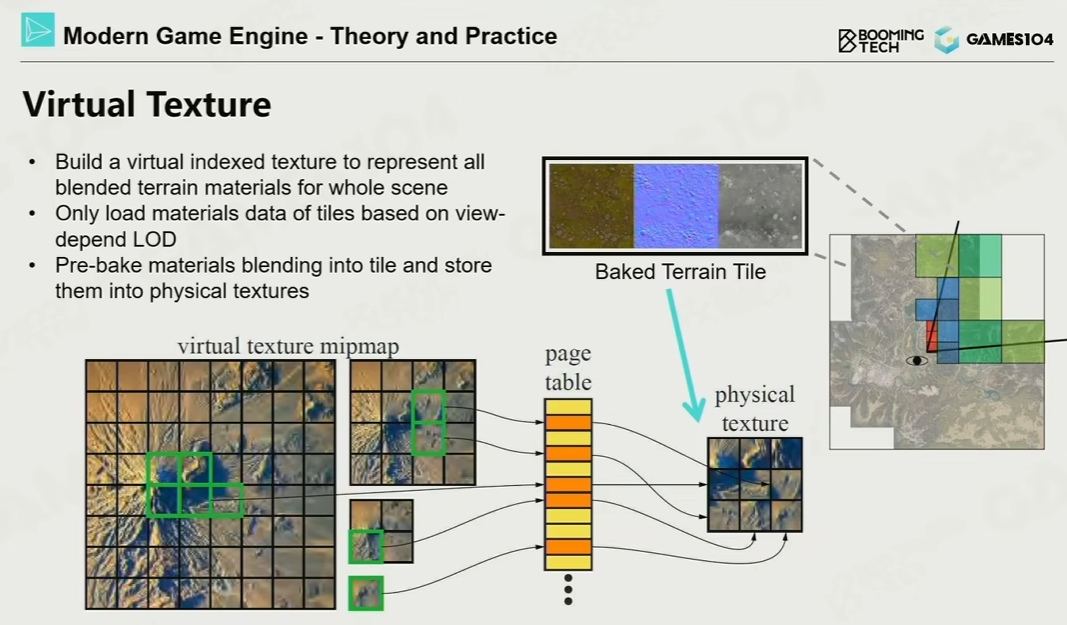
虚拟纹理可以说是在内存中只存储纹理的一部分,而不是整个纹理的纹理,这项技术是由约翰·卡马克 (John Carmack) 在 id Software 开发《Rage》时首次普的。使用传统纹理时,整个纹理必须加载到内存中,但使用虚拟纹理时,可以仅加载和使用必要的部分。因此,虚拟纹理是一种可以减少内存使用的技术。 每个数据都以图块为单位存储,忽略纹理的位置连续性。这样的机制不仅仅减少了带宽消耗和内存(显存)消耗,也带来了其他好处,比如有利于合批,而不用因为使用不同的Texture而打断合批,这样可以根据需求来组织几何使得更利于Culling,当然合批的好处是states change 变少。LightMap也可以预计算到一张大的Virtual Texture上,用来合批。
在UE中,提供了两种虚拟纹理,分别为Runtime Virtual Textures(RVT)和Streaming Virtual Textures(SVT)。两者区别如下:
| Runtime Virtual Textures | Streaming Virtual Textures |
| - 支持超高纹理分辨率。 - 按需将纹素数据缓存于内存中。 - 运行时由GPU生成的纹素数据。 - 非常适用于可按需渲染的纹理数据,如过程纹理或合成分层材质。 | - 支持超高纹理分辨率。 - 按需将纹素数据缓存于内存中。 - 在硬盘中烘焙和加载纹素数据。 - 非常适用于生成时间较长的纹理数据,如光照贴图或美术师创建的大型细节纹理。 |
1.虚拟纹理内存池
虚拟纹理系统主要有两种GPU内存分配方式:页表内存(Page Table Memory)和物理内存池(Physical Memory Pool)。
- 页表内存(Page Table Memory) 提供了从纹理坐标间接访问纹理数据的方法,可以按需分配。它会随着时间推移不断增大;除非释放其中的全部内容,否则无法从内存中释放。用户无法控制该存储类型。
- 物理内存池(Physical Memory Pool) 包含了当前驻留的纹理数据,并且由多个独立的池构成。虚拟纹理系统所查看的每一种纹理格式都有对应的内存池。对应格式的虚拟纹理进行第一次实例化时会分配内存池。每个内存池都具有固定的大小,不会逐渐增大。用户可以控制每个池的大小。
物理内存池都是由页组成的。每一页都包含了一个虚拟纹理区块的数据。内存池的行为类似于以使用时间远近为基础的缓存。当虚拟纹理系统请求区块时,它就会被流送或渲染到内存池里的一个可用页中。如果没有可用页,那么包含使用时间最久远的区块的页就会被去除,为新区块腾出空间。
如果视图中包含的可见虚拟纹理过多,无法存储到虚拟纹理内存池中,系统就无法正确渲染视图。在这些情况下,必须调整虚拟纹理内存池的大小,从而满足数据使用量要求。
1.1 地址映射
地址映射在Virtual Texture是一个很重要的环节,就是如何将一个Virtual Texture的texel映射到Physical Texture的texel上,这里还需要适配当高分辨率的page没有加载的情况,需要得到已经加载的对应低分辨率的page地址。
1.1.1 四叉树映射
使用四叉树主要是为了和mipmap对应,也就是每个低mip的map会对应有四个高mip的map,四叉树中只存储加载的mipmap信息。这里的对应关系就是每个加载的Virtual Texture的page对应一个四叉树的节点,具体的计算如下:

这里每个四叉树的节点的内容存的就是bias和scale,这样就可以将虚拟纹理的地址转换成物理纹理的地址了,假如没有找到,也可以用父节点的地址来得到低分辨率的。但是这里要找到对应的节点需要搜索这个四叉树,搜索的速度取决于树的高度,也就是mipmap的层级,在差的低mip的地址上效率会比较差。
1.1.2 单像素对应虚纹理的一个page的映射
为了减少索引,首先容易想到的就是,为每个虚纹理的page都存储一份信息,这样就能直接转换了。这个方案就是创建一个带mipmap的texture,一个texel对应虚纹理的一个page,texel的内容就是四叉树映射里面的bias和scale。假如对应的mip没有加载,存储的就是高mip的转换信息。这样显然就提高了地址转换的效率,但是,带来了内存增加,我们需要每个虚纹理的page都对应一个texel。其中bias和scale都是2维的向量,即使设计虚纹理和物理纹理的比例一致,我们也需要至少scale,Sbias,Tbias三个量,而且这三个量的精度要求很高,至少需要16bit的浮点数精度,如果要达到这样的精度就需要,F32*4的纹理格式,那就会产生一个巨大的映射纹理,需要减小映射纹理的大小。
1.1.3 双纹理映射
这个方案仍然有一个对应每个虚纹理page的texture,但是不同的是,纹理的内容存储的是物理纹理page的坐标,用这个坐标再去索引另外一张texture。另外一张贴图的内容才是bias和scale,但是不是每个虚拟纹理,而是每个物理纹理page一个texel。这个是虚拟纹理对应的texture的样子:
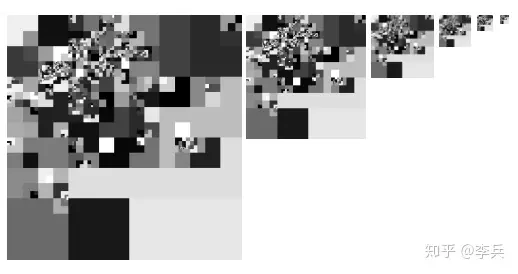
这样一来,就减少了映射纹理的大小了,但是同时带来了多一次的纹理查询。
1.1.4 page和mip level映射
总结上面两个基于映射纹理的方案,要么是纹理需要很大的存储,要么是需要多次查询。如果从映射纹理比较大的角度考虑优化的话,可以考虑适当减少每个像素的大小,这个方案就是从这个角度出发的。这个方案中,仍然是每个虚拟纹理的page对应一个texel,但是存储的内容是物理纹理page的offset和虚拟纹理所在的mip level。
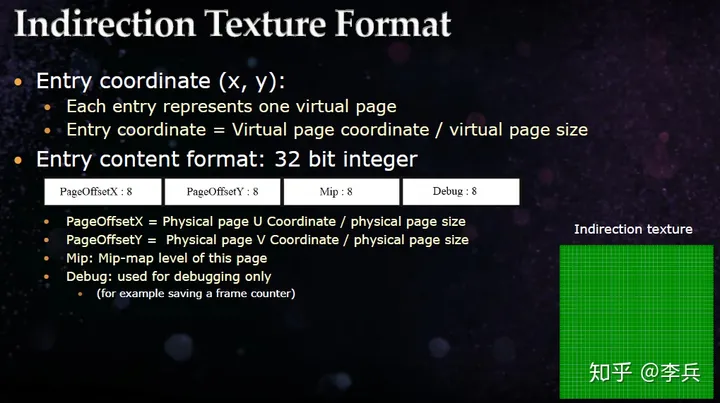
这样的存储的好处就是,page offset对精度的要求没有那么大了,用32bit的texture就可以了。当然了,也可以压缩到更小格式的纹理里,如RGB565。这种方案是被使用最广泛的,基本各家引擎的实现都是用了这种方案。
1.1.5 HashTable映射
这是最直接的方法,好处是节省内存,查询速度也快,但是,当遇到没有加载的virtual page的时候,需要多次查询。这个和四叉树还有一个问题,就是如何设计一个GPU友好的数据结构也是个问题。
2. UE VT使用
开启UE选项中的VT后,需要放置RuntimeVirtualTextureVolume,生成RVT。

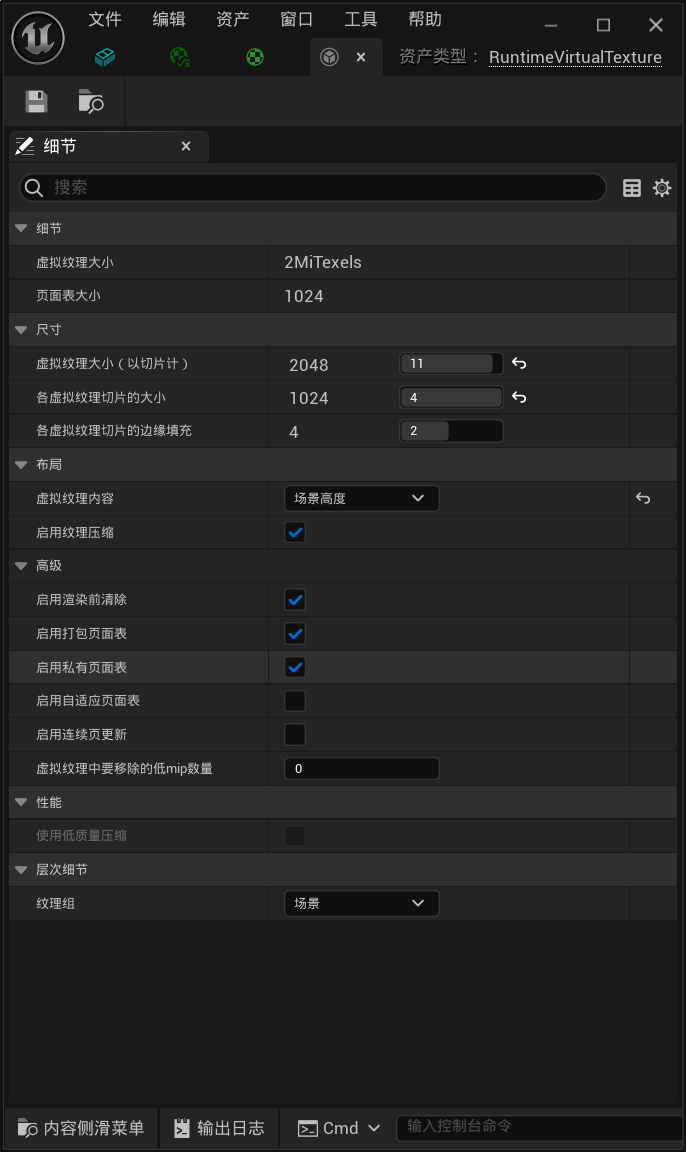
可以编辑设置虚拟纹理相关属性:
蓝图组件:
引用&参考
1.https://zhuanlan.zhihu.com/p/138484024
2.https://discourse.threejs.org/t/virtual-textures/53353
3.https://docs.unrealengine.com/5.3/zh-CN/virtual-texture-memory-pools-in-unreal-engine/