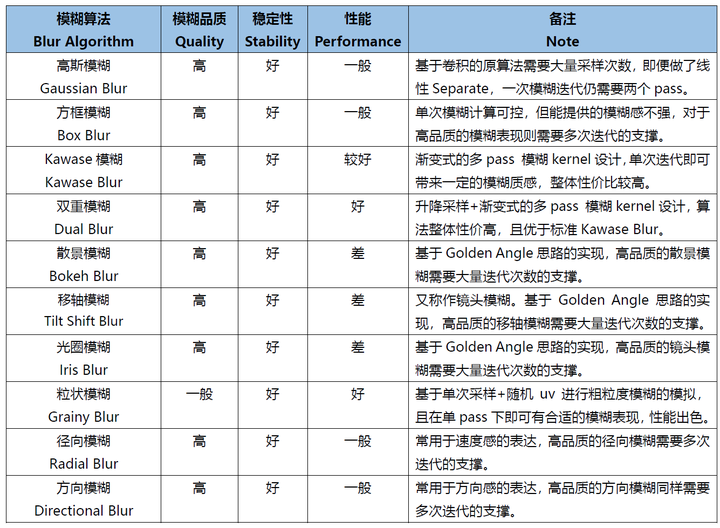
模糊的实现方法有很多种,传统的高斯模糊性能消耗很高,本文在模糊的实现方式上参考了浅墨前辈(r.i.p)提供的测试结果 和 开源库等资料。URP下的模糊网上的实现大多都是比较传统的双Pass高斯模糊,关于DualKawaseBlur URP实现我没找到现成的轮子, 外网的讨论也很少。不过DualKawaseBlur的实现方式从build in改过来也相对简单,正好自己网站花了2天经历调教好了,就试试新的编辑器顺便写下实现方式吧。未来再把之前的一些整理好的文档搬到网站上来。
DualKawaseBlur原理/比较
模糊本质上是个低通滤波器,过滤掉图像中的高频信息。好了,专注于实现的小伙伴可以跳过这部分不看了,记住这句话就够了。
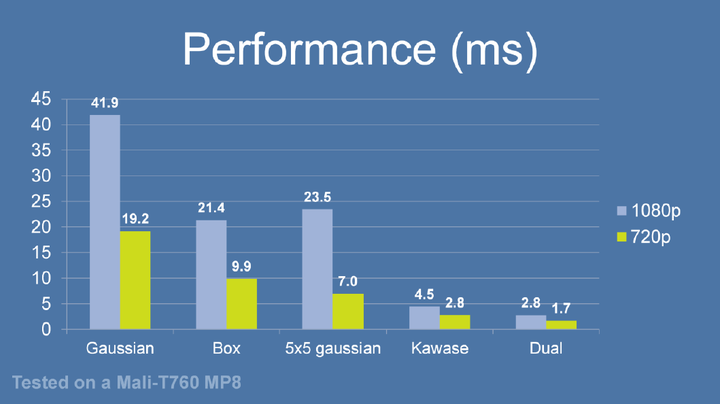
DualKawaseBlur 就是在Kawase Blur的基础上升降采样.那Kawase Blur是什么呢?
以下引用自浅墨大佬原文(懒orz):
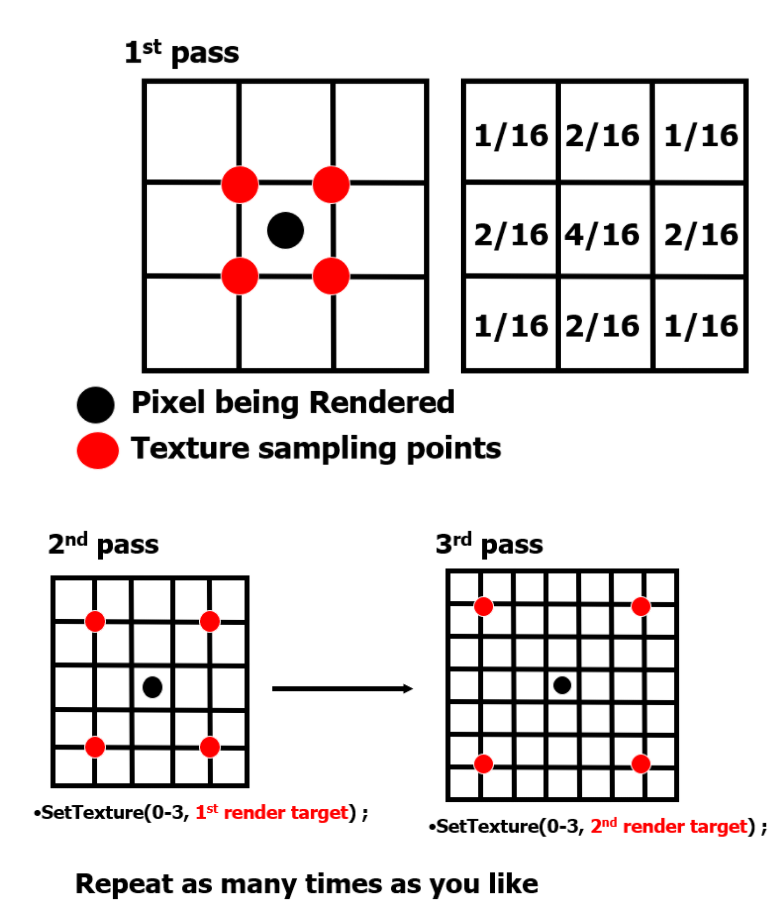
Kawase Blur于Masaki Kawase 在GDC2003的分享《Frame Buffer Postprocessing Effects in DOUBLE-S.T.E.A.L (Wreckless)》中提出。Kawase Blur最初用于Bloom后处理特效,但其可以推广作为专门的模糊算法使用,且在模糊外观表现上与高斯模糊非常接近。 Kawase Blur的思路是对距离当前像素越来越远的地方对四个角进行采样,且在两个大小相等的纹理之间进行乒乓式的blit。创新点在于,采用了随迭代次数移动的blur kernel,而不是类似高斯模糊,或box blur一样从头到尾固定的blur kernel。
Q:利用computer shader做模糊效果对比传统的方式是否更有优势?
根据Intel这篇文章的测试(这篇文章讲的高斯模糊的优化也非常好),在大filter下computer shader才相对有优势,所以说computer shader绝对有优势是不对的。不过这篇测试文章也有一定的年头了,实际性能还是需要真机上跑一跑。不过我这里就懒得测试了,因为即使有优势差距也不会太大。而且作者也表达了用computer shader不够“tweakable”。


RenderFeature 核心代码
感觉没啥要讲的233,简单来说核心就是升降采样
//downSample
for (int i = 0; i < settings.blurPasses;i++)
{
cmd.GetTemporaryRT(downSampleRT[i], tw, th, 0, FilterMode.Bilinear, RenderTextureFormat.ARGB32);
cmd.GetTemporaryRT(upSampleRT[i], tw, th, 0, FilterMode.Bilinear, RenderTextureFormat.ARGB32);
tw = Mathf.Max(tw / 2, 1);
th = Mathf.Max(th / 2, 1);
cmd.Blit(tmpRT, downSampleRT[i], settings.material, 0);
tmpRT = downSampleRT[i];
}
//upSample
for(int i = settings.blurPasses - 2; i >= 0; i--)
{
cmd.Blit(tmpRT,upSampleRT[i], settings.material, 1);
tmpRT = upSampleRT[i];
} DualKawaseBlurShader
//downSample Pass
v2f vert (appdata v)
{
v2f o;
o.vertex = TransformObjectToHClip(v.vertex.xyz);
o.uv = v.uv;
#if UNITY_UV_STARTS_TOP
o.uv.y = 1 - o.uv.y;
#endif
_MainTex_TexelSize *= 0.5;
float2 offset = float2(1 + _Offset, 1 + _Offset);
o.uv01.xy = o.uv - _MainTex_TexelSize * offset;
o.uv01.zw = o.uv + _MainTex_TexelSize * offset;
o.uv23.xy = o.uv - float2(_MainTex_TexelSize.x, -_MainTex_TexelSize.y) * offset;
o.uv23.zw = o.uv + float2(_MainTex_TexelSize.x, -_MainTex_TexelSize.y) * offset;
return o;
}
half4 frag (v2f i) : SV_Target
{
half4 col = SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv) * 4;
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv01.xy);
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv01.zw);
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv23.xy);
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv23.zw);
return col * 0.125;
}
//UpSample Pass
v2f vert (appdata v)
{
v2f o;
o.vertex = TransformObjectToHClip(v.vertex.xyz);
o.uv = v.uv;
#if UNITY_UV_STARTS_TOP
o.uv.y = 1 - o.uv.y;
#endif
_MainTex_TexelSize *= 0.5;
float2 offset = float2(1 + _Offset, 1 + _Offset);
o.uv01.xy = o.uv + float2(-_MainTex_TexelSize.x * 2, 0) * offset;
o.uv01.zw = o.uv + float2(-_MainTex_TexelSize.x, _MainTex_TexelSize.y) * offset;
o.uv23.xy = o.uv + float2(0, _MainTex_TexelSize.y * 2) * offset;
o.uv23.zw = o.uv + _MainTex_TexelSize * offset;
o.uv45.xy = o.uv + float2(_MainTex_TexelSize.x * 2, 0) * offset;
o.uv45.zw = o.uv + float2(_MainTex_TexelSize.x, -_MainTex_TexelSize.y) * offset;
o.uv67.xy = o.uv + float2(0, -_MainTex_TexelSize.y * 2) * offset;
o.uv67.zw = o.uv - _MainTex_TexelSize * offset;
return o;
}
half4 frag (v2f i) : SV_Target
{
half4 col = 0;
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv01.xy);
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv01.zw) * 2;
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv23.xy);
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv23.zw) * 2;
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv45.xy);
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv45.zw) * 2;
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv67.xy);
col += SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, i.uv67.zw) * 2;
return col * 0.0833;
}效果


引用&参考
- https://zhuanlan.zhihu.com/p/125744132
- https://github.com/QianMo/X-PostProcessing-Library
- https://www.intel.com/content/www/us/en/developer/articles/technical/an-investigation-of-fast-real-time-gpu-based-image-blur-algorithms.html
- https://github.com/alex47/Dual-Kawase-Blur/tree/master/shaders
- 2015 paper (.pdf)